检索增强生成(Retrieval Augmented Generation)
检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。
理解不难,就是通过自有垂域数据库检索相关信息,然后合并成为提示模板,给大模型生成漂亮的回答。
经历23年年初那一波大模型潮,想必大家对大模型的能力有了一定的了解,但是当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因:
- 知识的局限性:
-
模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
-
幻觉问题:
-
所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
-
数据安全性:
- 对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
而RAG是解决上述问题的一套有效方案。
一句话总结:RAG(中文为检索增强生成) = 检索技术 + LLM 提示。例如,我们向 LLM 提问一个问题(answer),RAG 从各种数据源检索相关的信息,并将检索到的信息和问题(answer)注入到 LLM 提示中,LLM 最后给出答案。
RAG 是2023年基于 LLM 的系统中最受欢迎的架构。许多产品基于 RAG 构建,从基于 web 搜索引擎和 LLM 的问答服务到使用私有数据的chat应用程序。
尽管在2019年,Faiss 就实现了基于嵌入的向量搜索技术,但是 RAG 推动了向量搜索领域的发展。比如 chroma、weaviate.io 和 pinecone 这些基于开源搜索索引引擎(主要是 faiss 和 nmslib)向量数据库初创公司,最近增加了输入文本的额外存储和其他工具。
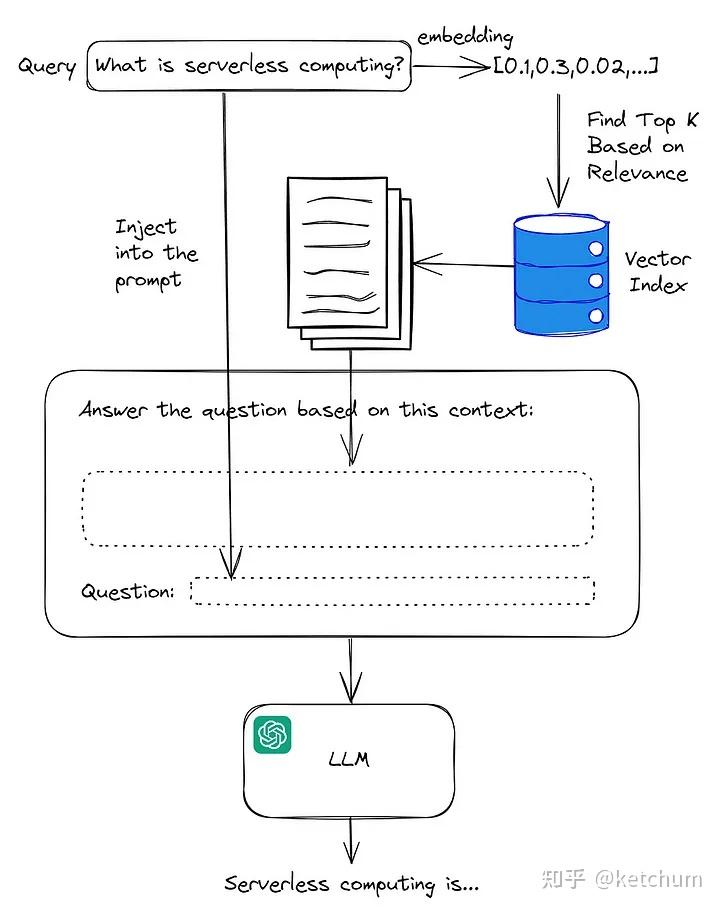
在这个过程中,有两个主要步骤:语义搜索和生成输出。在语义搜索步骤中,我们希望从我们的知识库中找到与我们要回答的查询最相关的部分内容。然后,在生成步骤中,我们将使用这些内容来生成响应。
有两个最著名的基于 LLM 的管道和应用程序的开源库——LangChain 和 LlamaIndex,受 ChatGPT 发布的启发,它们在 2022 年 10 月和 11 月创立,并在 2023 年获得大量采用。
本文的目的是参考 LlamaIndex实现,来系统讲解关键的高级 RAG 技术,以方便大家深入研究。 问题在于,大多数教程只会针对个别技术进行详细讲解,而不是整体全面地系统化归纳总结。 另一件事是,LlamaIndex 和 LangChian 都是了不起的开源项目,他们的开发速度非常快,以至于他们的文档已经比2016年的机器学习教科书还要厚。
RAG实现过程
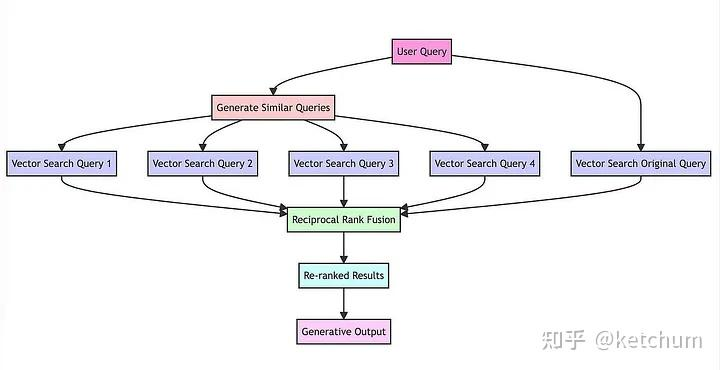
目前我们已经知道 RAG 融合是一种用于(可能)提升 RAG 应用检索阶段的技术。在这个部分里,我会简单阐述我的观点,不过如果你想知道更多详细信息,你可以查阅这篇文章。
下面这张图片展示了大概的工作流程。基本上,主要思路就是利用 LLM 来生成多个查询,期望能够通过这些查询让问题的各个方面在上下文中显现出来。之后你可以使用生成的查询进行向量搜索(如本系列之前的部分所述),并且基于其在结果集中的显示方式来对内容进行重新排序。