海量定时任务中间件
基于Redis(zset和list)、HashedWheelTimer、Netty实现的分布式、高可用、高吞吐、任意延时的海量定任务中间件。
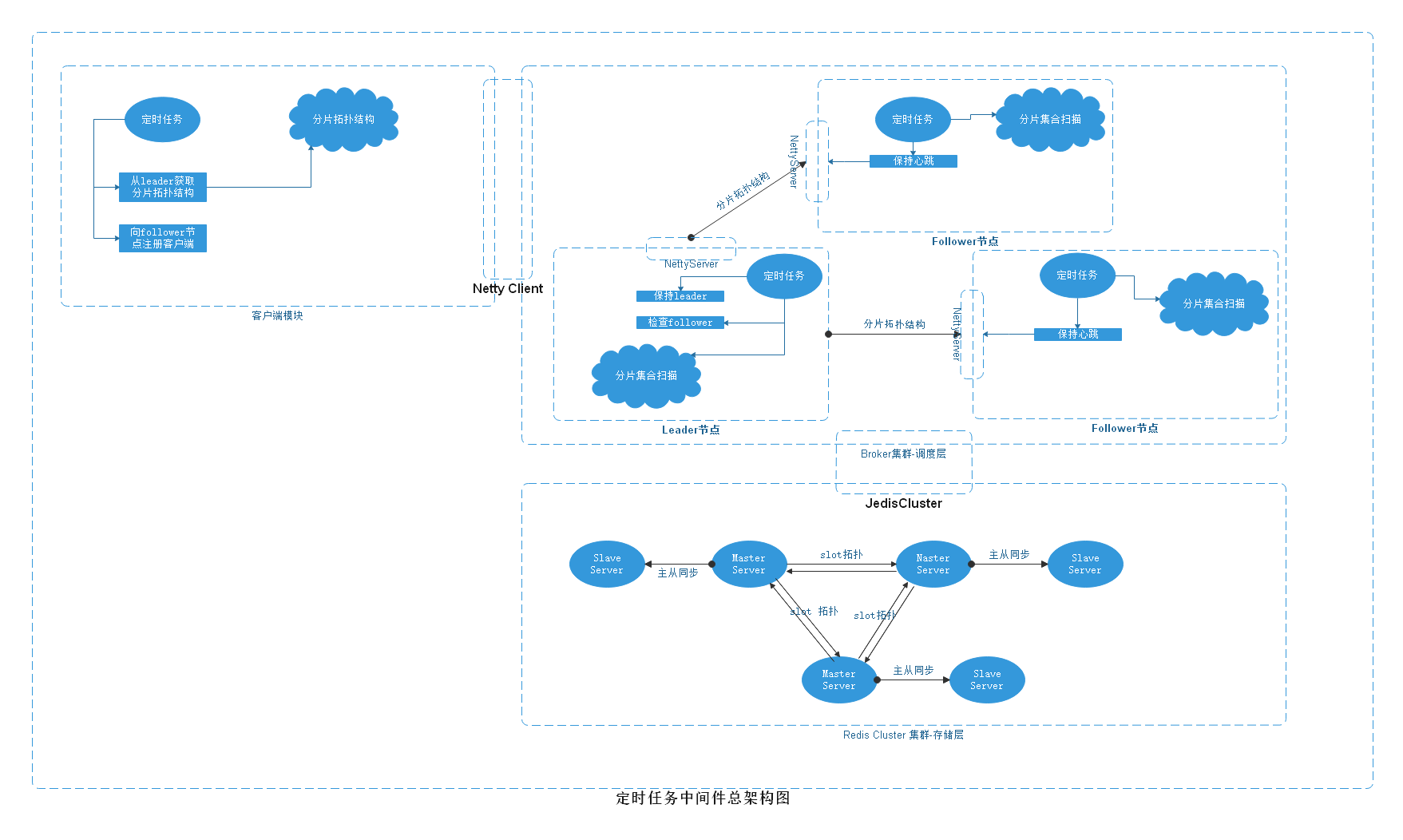
1、总架构图
2、定时处理模块
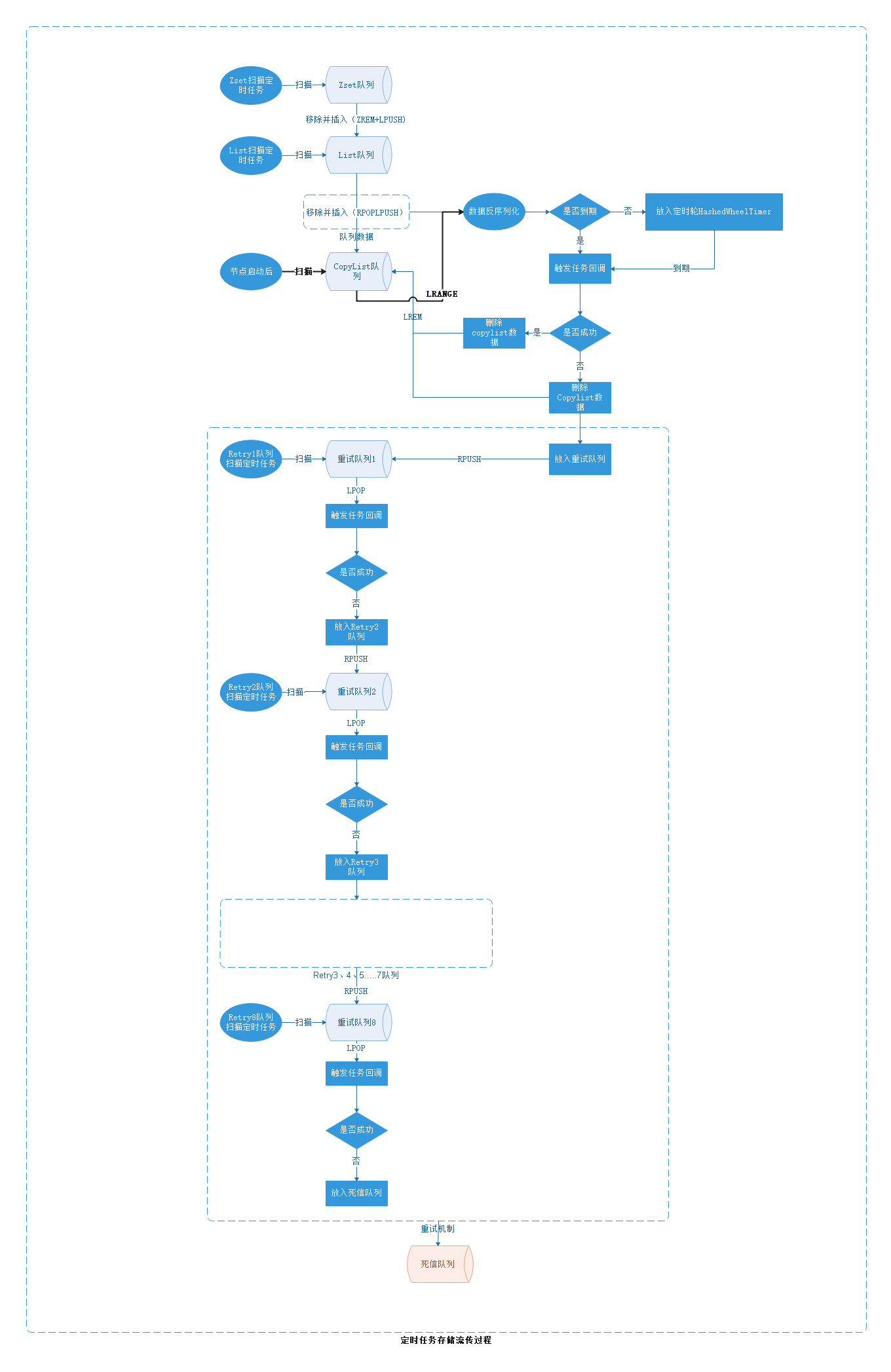
2.1、定时模块流程图
基于redis的zset和list数据结构,实现任务的定时触发、安全备份、重试处理和死信队列。 基于HashedWheelTimer实现基于broker内存级别的定时任务触发。
2.2、定时模块原理
2.2.1、zset扫描入list过程
-- lua脚本
-- 获取结果
local result = redis.call('ZRANGEBYSCORE',KEYS[1],ARGV[1],ARGV[2],'LIMIT', ARGV[3] ,ARGV[4])
-- 遍历元素,从zset删除,放入list
for k, v in pairs(result) do
redis.call('LPUSH',KEYS[2],v)
redis.call('ZREM',KEYS[1],v)
end
return #result
2.2.2、从list顺序读取到copylist中
-- 获取数据并备份到另一个list中,触发成功删除,失败加入retry队列
local result = {}
local page = ARGV[1];
for var=0,page do
local re = redis.call('RPOPLPUSH',KEYS[1],KEYS[2]);
if(re)
then
table.insert(result,re)
else
break
end
end
return result
// 回调处理器
if (triggerTime <= System.currentTimeMillis()) {
if (callBackProcessor.trigger(xtimerRequest)) {
deleteCopy(copyKey, value);
}else{
jedisCluster.rpush(retryKey, xtimerRequest.getCallBackTime(), value);
}
} else {
timer.newTimeout(timeout -> {
if (callBackProcessor.trigger(xtimerRequest)) {
deleteCopy(copyKey, value);
}else {
jedisCluster.rpush(retryKey, xtimerRequest.getCallBackTime(), value);
}
}, triggerTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
2.2.3、节点启动后扫描copylist中的数据,做恢复检查
local result = redis.call("LRANGE",KEYS[1],ARGV[1],ARGV[2])
-- 将返回结果遍历一遍
if (triggerTime <= System.currentTimeMillis()) {
if (callBackProcessor.trigger(xtimerRequest)) {
deleteCopy(copyKey, value);
}else{
jedisCluster.rpush(retryKey, xtimerRequest.getCallBackTime(), value);
}
} else {
hashedWheelTimer.newTimeout(timeout -> {
if (callBackProcessor.trigger(xtimerRequest)) {
deleteCopy(copyKey, value);
}else{
jedisCluster.rpush(retryKey, xtimerRequest.getCallBackTime(), value);
}
}, triggerTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
2.3、重试模块
-- 获取重试队列结果
redis.lpop(retryKey)
-- 获取结果遍历触发,触发失败放入重试次数+1队列中
if (callBackProcessor.trigger(xtimerRequest)) {
deleteList(listKey, value);
}else{
jedisCluster.lpush(retryKey+1,value);
}
-- 重试次数达到一定值后放入死信队列
redis.lpush(deadKey,value)
3、集群高可用
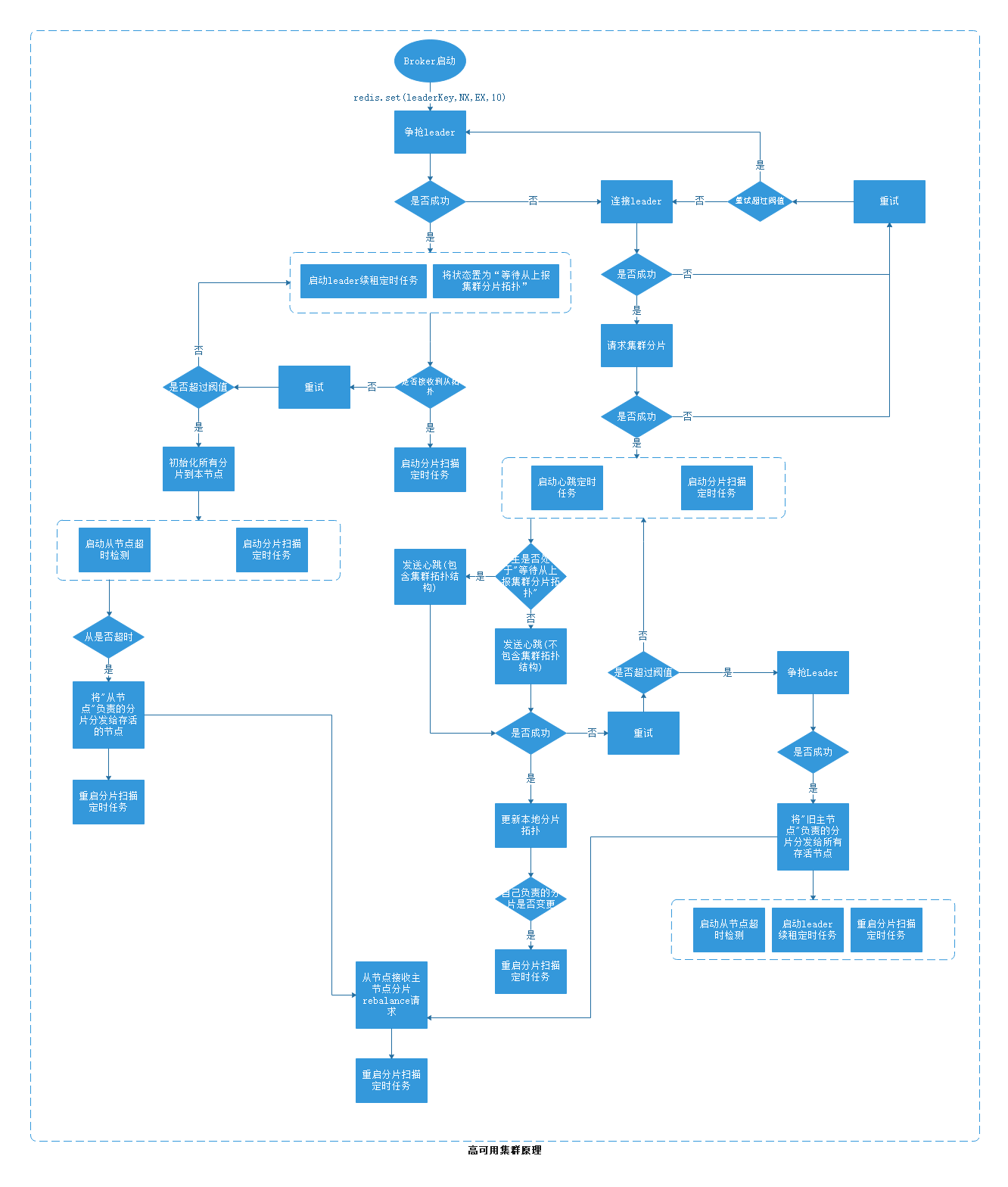
3.1、高可用流程图
保证每时每刻每个分片都有负责扫描的borker,为什么不用zk来保存集群拓扑结构? 1. 在网络不稳定的情况下会造成频繁的临时节点断掉和连接,造成集群拓扑结构一直处于rebalance状态。 2. 引入zk这个重量级中间件,对集群的维护造成额外的压力。
3.2、高可用原理
1. broker间通讯用Netty
2. broker 启动后在redis注册leader key,注册成功就是leader角色broker。
3. 启动注册失败就是follower角色broker
4. leader角色broker定时对redis leader key续租,定时检测follower broker是否超时。
5. follower broker 定时发送心跳到leader broker,leader borker接收到心跳后发送 分片拓扑结构给follower。
6. follower心跳连接不上leader超过一定次数后认定leader 挂掉,follower争抢leader角色,争抢成功,关闭旧的心跳定时任务,开启leader 角色续租和follower 检测定时任务
7. follower争抢leader失败后,不做任何操作,等待新leader通知其更新分片拓扑结构,接收到新的拓扑结构后向新的leader发送心跳。
4、分片原理
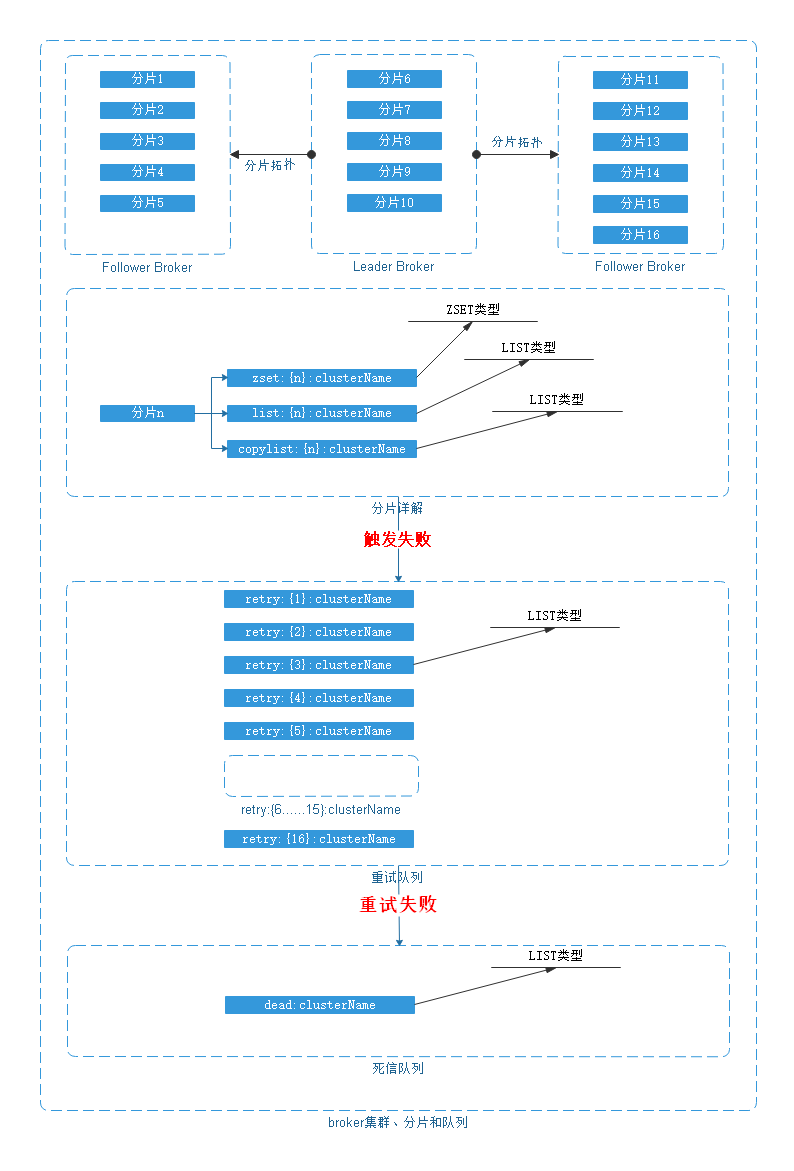
4.1、分片图解
4.2、分片详解
1. 以clusterName区分broker端集群,以groupKey和appKey区分客户端。
2. 同一集群进行zset list copylist retry 分片,分片形式:[zset|list|copy|retry{num}]:{partition}:clusterName
3. follower broker在启动时会向leader broker申请要负责扫描的key列表,获取到key列表后本机broker启动。
1. copylist check worker
2. zset 扫描worker
3. list 扫描到copylist worker
4. 如果启动时争抢leader成功,把所有的分片划到自己负责的key列表中,等待follower连接上来后分配key列表给follower。
5. follower挂掉后,将挂掉的broker分配的key列表分配给存活的broker(leader+follower),并启动broker rebalance。
6. 分片数目在集群创建时就已确定,不再更改。
5、客户端注册
5.1、客户端流程图
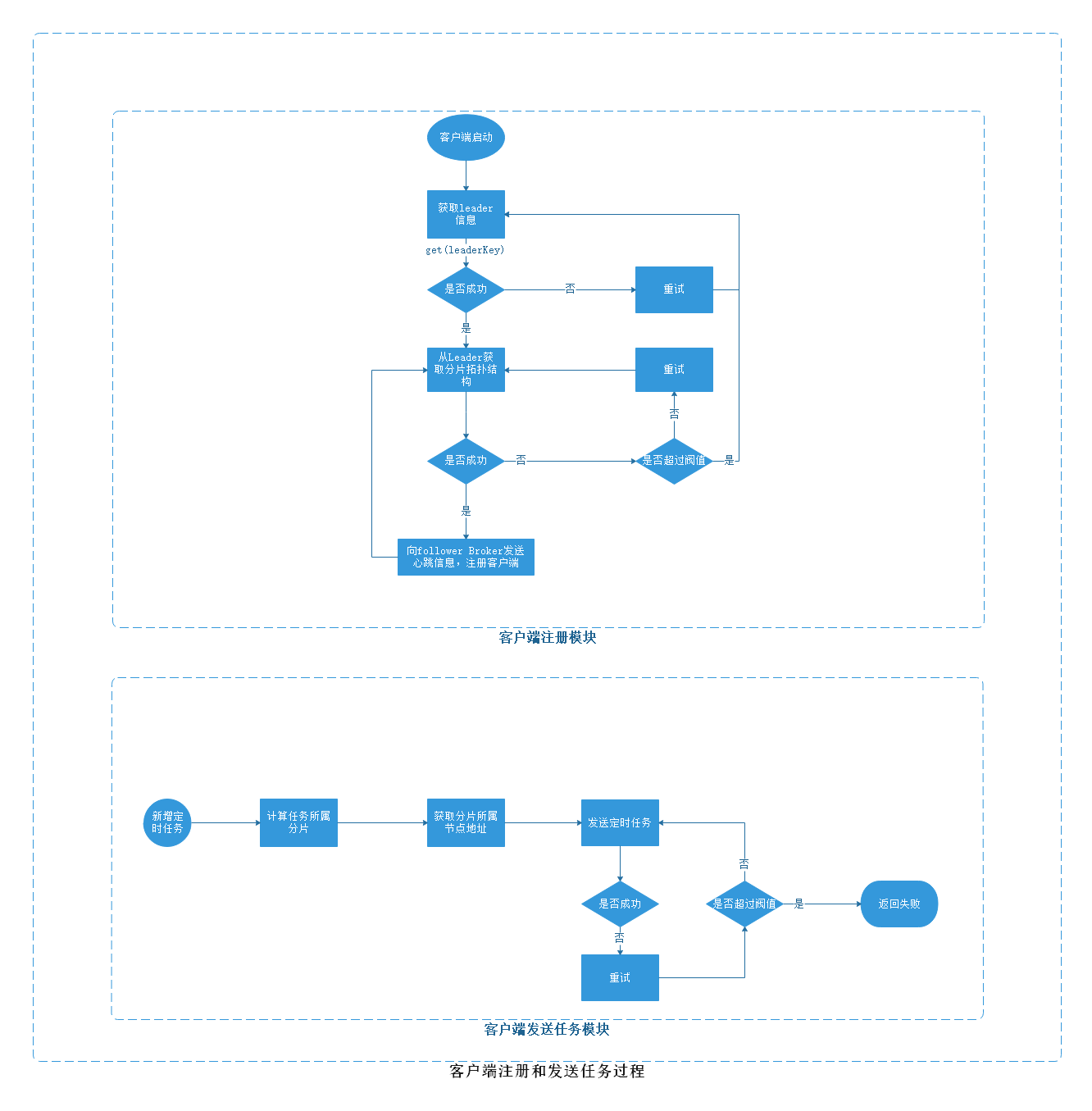
5.2、注册步骤
1. 客户端启动后从redis读取leader broker信息,LEADER:{CLUSTER_NAME}
2. 连接leader,并从leader broker请求broker分片拓扑图,如下。
{
"127.0.0.1:10000": {
"lastHeartBeat": 1596452434862,
"addr": "127.0.0.1:10000",
"serveKeys": [
"zset:{0}:xtimer_tcc",
"zset:{1}:xtimer_tcc"
]
},
"127.0.0.2:10000": {
"lastHeartBeat": 1596452438390,
"addr": "127.0.0.2:10000",
"serveKeys": [
"zset:{2}:xtimer_tcc",
"zset:{3}:xtimer_tcc"
]
},
"127.0.0.3:10000": {
"lastHeartBeat": 1596452438224,
"addr": "127.0.0.3:10000",
"serveKeys": [
"zset:{4}:xtimer_tcc",
"zset:{5}:xtimer_tcc"
]
}
}
3. 客户端定时向所有broker(leader+follower)发送注册心跳,包含:groupKey和appKey信息。
4. broker维护客户端注册列表,以groupKey和appKey区分。
5. 当定时任务触发后,broker端根据待触发任务存储的信息groupKey和appKey选择(负载均衡
)一个客户端channel进行任务回调。
6. 客户端接收到回调后执行回调业务,返回结果,若成功,borker将定时任务从copylist删除,否则放入重试队列,重试超过一定次数会放入死信队列。
6、触发保证
最少一次:保证至少触发一次
精确一次:保证至少触发一次,客户端对触发做去重
至多一次:Broker端发送事件触发后直接删除copylist的数据