Page Cache 和 Zero Copy
RocketMQ零拷贝?Netty零拷贝?kafka零拷贝?到底是个什么玩意儿!什么page cache?什么是顺序读,什么是顺序写?到底能提升多少性能?MMAP是什么?sendfile()是什么?splice是什么?
基础知识篇
每个进程中都有一个用户文件描述符表,表项指向一个全局的文件表中的某个表项,文件表表项有一个指向内存inode的指针,每个inode唯一标识一个文件。如果同时有多个进程打开同一文件,他们的用户文件描述符表项指向不同的文件表项,但是这些文件表项会指向同一个inode。
Page Cache
内核会为每个文件单独维护一个page cache,用户进程对于文件的大多数读写操作会直接作用到page cache上,内核会选择在适当的时候将page cache中的内容写到磁盘上(一般会定时或者手工fsync控制回写(例如elasticsearch会定时5s从cache里刷到segment file日志文件),这样可以大大减少磁盘的访问次数,从而提高性能。
Page cache是linux内核文件访问过程中很重要的数据结构,page cache中会保存用户进程访问过得该文件的内容,这些内容以页为单位保存在内存中,当用户需要访问文件中的某个偏移量上的数据时,内核会以偏移量为索引,找到相应的内存页,如果该页没有读入内存,则需要访问磁盘读取数据。为了提高页得查询速度同时节省page cache数据结构占用的内存,linux内核使用树来保存page cache中的页。
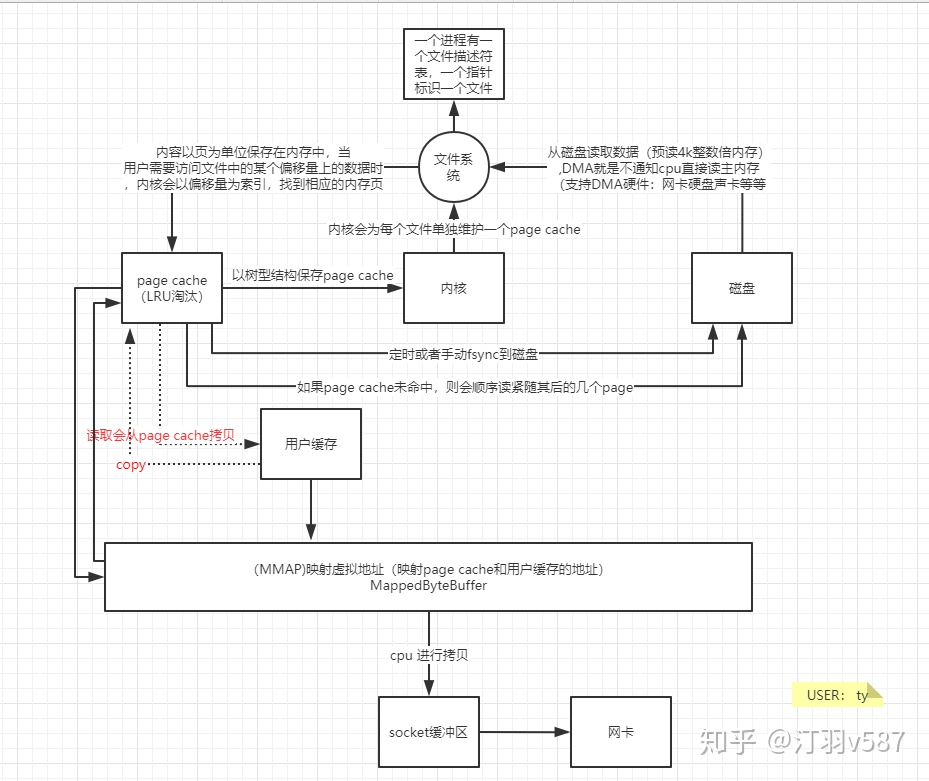
讲讲JAVA中的IO
-
普通IO(java.io)
- 例如FileWriter、FileReader等,普通IO是传统字节传输方式,读写慢阻塞,单向一个Read对应一个Write
-
文件通道
java FileChannel(java.nio) FileChannel fileChannel = new RandomAccessFile(new File("data.txt"), "rw").getChannel()- 全双工通道,可以同时读和写,采用内存缓冲区ByteBuffer且是线程安全的 - 使用FileChannel为什么会比普通IO快?一般情况FileChannel在一次写入4kb的整数倍数时,才能发挥出实际的性能,益于FileChannel采用了ByteBuffer这样的内存缓冲区。这样可以精准控制写入磁盘的大小,这是普通IO无法实现-
FileChannel是直接把ByteBuffer的数据直接写入磁盘?
ByteBuffer 中的数据和磁盘中的数据还隔了一层,这一层便是 PageCache,是用户内存和磁盘之间的一层缓存。我们都知道磁盘 IO 和内存 IO 的速度可是相差了好几个数量级。我们可以认为 filechannel.write 写入 PageCache 便是完成了落盘操作,但实际上,操作系统最终帮我们完成了 PageCache 到磁盘的最终写入,理解了这个概念,你就应该能够理解 FileChannel 为什么提供了一个 force() 方法,用于通知操作系统进行及时的刷盘,同理使用FileChannel时同样经历磁盘->PageCache->用户内存三个阶段
-
-
内存映射MMAP(java.nio)
java MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, position, fileSize)- mmap 把文件映射到虚拟内存,省去了从page cache复制到用户缓存的过程
-
由native方法transferTo0()来实现,它依赖底层操作系统的支持。在UNIX和Linux系统中,调用这个方法将会引起sendfile()系统调用。
java File file = new File("test.zip"); RandomAccessFile raf = new RandomAccessFile(file, "rw"); FileChannel fileChannel = raf.getChannel(); SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("", 1234)); // 直接使用了transferTo()进行通道间的数据传输 fileChannel.transferTo(0, fileChannel.size(), socketChannel);
MappedByteBuffer 在 JAVA 中使用也会有局限性
- MMAP 使用时必须实现指定好内存映射的大小,并且一次 map 的大小限制在 1.5G 左右,重复 map 又会带来虚拟内存的回收、重新分配的问题,对于文件不确定大小的情形实在是太不友好了。
- MMAP 使用的是虚拟内存,和 PageCache 一样是由操作系统来控制刷盘的,虽然可以通过 force() 来手动控制,但这个时间把握不好,在小内存场景下会很令人头疼。
- MMAP 的回收问题,当 MappedByteBuffer 不再需要时,可以手动释放占用的虚拟内存,但…方式非常的诡异
page cache的一些缺点
- 当遇到OS进行脏页回写,内存回收,内存swap等情况时,就会引起较大的消息读写延迟
RocketMQ针对于page cache的缺点做了一些优化
-
预分配MappedFile
在消息写入过程中(调用CommitLog的putMessage()方法),CommitLog会先从MappedFileQueue队列中获取一个 MappedFile,如果没有就新建一个;这里,MappedFile的创建过程是将构建好的一个AllocateRequest请求(具体做法是,将下一个文件的路径、下下个文件的路径、文件大小为参数封装为AllocateRequest对象)添加至队列中,后台运行的AllocateMappedFileService服务线程(在Broker启动时,该线程就会创建并运行),会不停地run,只要请求队列里存在请求,就会去执行MappedFile映射文件的创建和预分配工作,分配的时候有两种策略:
一种是使用Mmap的方式来构建MappedFile实例,另外一种是从TransientStorePool堆外内存池中获取相应的DirectByteBuffer来构建MappedFile(ps:具体采用哪种策略,也与刷盘的方式有关)。
-
在创建分配完下个MappedFile后,还会将下下个MappedFile预先创建并保存至请求队列中等待下次获取时直接返回。RocketMQ中预分配MappedFile的设计非常巧妙,下次获取时候直接返回就可以不用等待MappedFile创建分配所产生的时间延迟
-
mlock系统调用
其可以将进程使用的部分或者全部的地址空间锁定在物理内存中,防止其被交换到swap空间。对于RocketMQ这种的高吞吐量的分布式消息队列来说,追求的是消息读写低延迟,那么肯定希望尽可能地多使用物理内存,提高数据读写访问的操作效率。后面有基于OS解决办法。
-
文件预热
预热的目的主要有两点;第一点,由于仅分配内存并进行mlock系统调用后并不会为程序完全锁定这些内存,因为其中的分页可能是写时复制的。因此,就有必要对每个内存页面中写入一个假的值。其中,RocketMQ是在创建并分配MappedFile的过程中,预先写入一些随机值至Mmap映射出的内存空间里。第二,调用Mmap进行内存映射后,OS只是建立虚拟内存地址至物理地址的映射表,而实际并没有加载任何文件至内存中。程序要访问数据时OS会检查该部分的分页是否已经在内存中,如果不在,则发出一次缺页中断。这里,可以想象下1G的CommitLog需要发生多少次缺页中断,才能使得对应的数据才能完全加载至物理内存中(ps:X86的Linux中一个标准页面大小是4KB)?RocketMQ的做法是,在做Mmap内存映射的同时进行madvise系统调用,目的是使OS做一次内存映射后对应的文件数据尽可能多的预加载至内存中,从而达到内存预热的效果。
PS:madvise,这个函数会传入一个地址指针,一个区间长度,madvise会向内核提供一个针对于于地址区间的I/O的建议,内核可能会采纳这个建议,会做一些预读的操作。例如MADV_SEQUENTIAL这个就表明顺序预读。 如果感觉这样还不给力,可以采用read操作,从mmap文件的首地址开始到最终位置,顺序的读取一遍,这样可以完全保证mmap后的数据全部load到内存中。
RocketMQ的消息采用顺序写到commitlog文件,然后利用consume queue文件作为索引;RocketMQ采用零拷贝mmap+write的方式来回应Consumer的请求;consumer在处理请求是用的mmap,这是网卡到磁盘的流程,但是在磁盘到网卡这个过程,也用到了sendfile,在java中就是transferTo()这个方法。
附带一下RocketMQ生产级OS调优参数:
-
vm-max_map_cout 开启的线程数默认是65536,如果做大数据,可能会不够,建议调大。
修改命令:echo 'vm.max_map_cout=655360' >>/etc/sysctl.conf
-
vm.swappiness 此参数是用来控制进程swap行为的,如果进程不太活跃,就会被操作系统把进程调整为睡眠状态,把进程的数据放入磁盘的swap区域,腾出自己的内存给其他活跃进程。修改范围(0~100),尽量调低,尽量别把进程放到磁盘swap区域,尽量使用物理内存
echo 'vm.swappiness=10' >> /etc/sysctl.conf
-
ulimit 控制最大文件链接数,默认值1024,在大量I/O时可能不够
echo 'ulimit -n 1000000 >>/etc/profile
-
vm.overcommit_memory
三个值(0,1,2)如果时0,中间件系统申请内存,如果操作系统觉得系统不够,会直接拒绝你的申请,导致申请内存失败,进而出现异常。如果是1,把所有可能的物理内存都允许分配给申请者,生产环境一般配1.
kafka当中的零拷贝
如上面一图,还有一层page cache与socket缓存之前cpu参与的拷贝,在内核2.1引入了sendfile(),sendfile()只能将数据从文件传递到套接字上,反之则不行。
sendfile(socket, file, len);
系统调用sendfile()发起后,磁盘数据通过DMA(见图1.1)方式读取到内核缓冲区,内核缓冲区中的数据通过DMA聚合网络缓冲区,然后一齐发送到网卡中。
我们仅仅需要把缓冲区描述符传到socket缓冲区,再把数据长度传过去,这样DMA控制器直接将页缓存中的数据打包发送到网络中就可以了。
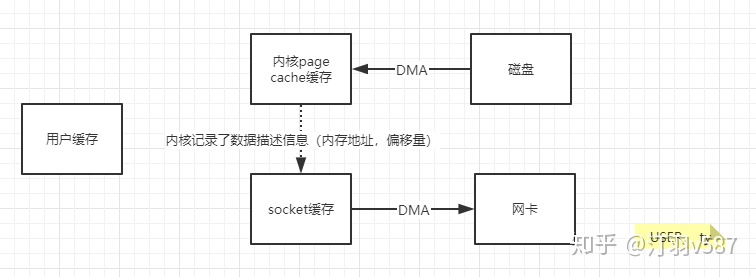
在内核2.6.17版本引入splice系统调用,用在两个文件描述符移动数据,其中一方必须是管道设备
-
splice()将数据从缓冲区移到任意文件描述符,反之亦然,或者从一个缓冲区到另一个缓冲区。
-
tee(2)将数据从一个缓冲区“复制”到另一个缓冲区。
-
vmsplice(2)将数据从用户空间“复制”到缓冲区中。
尽管我们谈论复制,但通常避免使用实际副本。内核通过将管道缓冲区实现为一组引用来实现此目的-
Netty中的零拷贝
Netty中也用到了FileChannel.transferTo方法,所以Netty的零拷贝也包括上面将的操作系统级别的零拷贝。
传统的ByteBuffer,如果需要将两个ByteBuffer中的数据组合到一起,我们需要首先创建一个size=size1+size2大小的新的数组,然后将两个数组中的数据拷贝到新的数组中。但是使用Netty提供的组合ByteBuf,就可以避免这样的操作,因为CompositeByteBuf并没有真正将多个Buffer组合起来,而是保存了它们的引用,从而避免了数据的拷贝,实现了零拷贝。
CompositeByteBuf:将多个缓冲区显示为单个合并缓冲区的虚拟缓冲区。 建议使用 ByteBufAllocator.compositeBuffer() or Unpooled.wrappedBuffer(ByteBuf...)
而不是显式调用构造函数。 我们引入一下源码
/**
* Cumulate {@link ByteBuf}s by add them to a {@link CompositeByteBuf} and so do no memory copy whenever possible.
* Be aware that {@link CompositeByteBuf} use a more complex indexing implementation so depending on your use-case
* and the decoder implementation this may be slower then just use the {@link #MERGE_CUMULATOR}.
通过将{@link ByteBuf}添加到{@link CompositeByteBuf}中来累积它们,因此尽可能不进行内存复制。
*请注意,{@ link CompositeByteBuf}使用更复杂的索引实现,因此取决于您的用例*和解码器实现,
与使用{@link #MERGE_CUMULATOR}相比,这可能会更慢
*/
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
public static final Cumulator COMPOSITE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
try {
if (cumulation.refCnt() > 1) {
// Expand cumulation (by replace it) when the refCnt is greater then 1 which may happen when the
// user use slice().retain() or duplicate().retain().
//
// See:
// - ByteToMessageDecoder has bug for expandCumulation · Issue #2327 · netty/netty
// - ByteBuf.discardSomeReadBytes() should skip discard if refCnt > 1 · Issue #1764 · netty/netty
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
buffer.writeBytes(in);
} else {
CompositeByteBuf composite;
if (cumulation instanceof CompositeByteBuf) {
composite = (CompositeByteBuf) cumulation;
} else {
composite = alloc.compositeBuffer(Integer.MAX_VALUE);
composite.addComponent(true, cumulation);
}
composite.addComponent(true, in);
in = null;
buffer = composite;
}
return buffer;
} finally {
if (in != null) {
// We must release if the ownership was not transferred as otherwise it may produce a leak if
// writeBytes(...) throw for whatever release (for example because of OutOfMemoryError).
in.release();
}
}
}
};
// 可以看出来这里用了ByteBufAllocator 来分配readable的空间,并写入累积器中
static ByteBuf expandCumulation(ByteBufAllocator alloc, ByteBuf cumulation, int readable) {
ByteBuf oldCumulation = cumulation;
cumulation = alloc.buffer(oldCumulation.readableBytes() + readable);
cumulation.writeBytes(oldCumulation); // 将原始累积器的数据copy到新的累积器
oldCumulation.release(); // 释放原始的累积器
return cumulation;
}
}
从这里我们可以看出netty也调用了FileChannelDe tansferTo方法
package io.netty.channel;
public class DefaultFileRegion extends AbstractReferenceCounted implements FileRegion {
private FileChannel file;
@Override
public long transferTo(WritableByteChannel target, long position) throws IOException {
long count = this.count - position;
if (count < 0 || position < 0) {
throw new IllegalArgumentException(
"position out of range: " + position +
" (expected: 0 - " + (this.count - 1) + ')');
}
if (count == 0) {
return 0L;
}
if (refCnt() == 0) {
throw new IllegalReferenceCountException(0);
}
// Call open to make sure fc is initialized. This is a no-oop if we called it before.
open();
long written = file.transferTo(this.position + position, count, target);
if (written > 0) {
transferred += written;
} else if (written == 0) {
// If the amount of written data is 0 we need to check if the requested count is bigger then the
// actual file itself as it may have been truncated on disk.
//
// See DefaultFileRegion.transferTo with invalid count may cause hang · Issue #8868 · netty/netty
validate(this, position);
}
return written;
}
}
分析一下一个TCP消息的传输过程
首先大家要明白 TCP保证消息顺序
主机每次发送数据时,TCP就给每个数据包分配一个 序列号 并且在一个特定的时间内等待接收主机对分配的这个序列号进行确认,如果发送主机在一个特定时间内没有收到接收主机的确认,则发送主机会重传此数据包。 接收主机利用序列号对接收的数据进行确认,以便检测对方发送的数据是否有丢失或者乱序等,接收主机一旦收到已经顺序化的数据,它就将这些数据按正确的顺序重组成数据流并传递到高层进行处理。
然后
TCP/IP的传输过程中,数据包有可能会被重新封装在不同的数据包中,例如当你发送如下数据时:
| 消息头 | 消息体 | ABC | DEF | GHI
有可能实际收到的数据如下:
| 消息头 | 消息体 |ABCD |EFGH | I
这样就出现了TCP的粘包黏包的问题(一个消息的消息体与另一个消息的消息头黏在一起了),netty有自己的解决方法,我这里提供一种生产级的解决方案
LengthFieldBasedFrameDecoder
大致的意思就是:消息发送时分别设置消息头的长度和消息体的长度,接收时根据长度来获取指定的数据,以固定的长度写入两个buffer中,然后将数据buffer的引用组合在一起,通过mmap,用户对收到的数据进行处理。
dubbo怎么来解决粘包的问题的

首先,dubbo也是使用了这种消息头+消息内容的一种协议
协议详情, 然后在做了一层封装
-
Magic - Magic High & Magic Low (16 bits)
标识协议版本号,Dubbo 协议:0xdabb
-
Req/Res (1 bit)
标识是请求或响应。请求: 1; 响应: 0。
-
2 Way (1 bit)
仅在 Req/Res 为1(请求)时才有用,标记是否期望从服务器返回值。如果需要来自服务器的返回值,则设置为1。
-
Event (1 bit)
标识是否是事件消息,例如,心跳事件。如果这是一个事件,则设置为1。
-
Serialization ID (5 bit)
标识序列化类型:比如 fastjson 的值为6。
-
Status (8 bits)
仅在 Req/Res 为0(响应)时有用,用于标识响应的状态。
-
20 - OK
-
30 - CLIENT_TIMEOUT
-
31 - SERVER_TIMEOUT
-
40 - BAD_REQUEST
-
50 - BAD_RESPONSE
-
60 - SERVICE_NOT_FOUND
-
70 - SERVICE_ERROR
-
80 - SERVER_ERROR
-
90 - CLIENT_ERROR
-
00 - SERVER_THREADPOOL_EXHAUSTED_ERROR
-
-
Request ID (64 bits)
标识唯一请求。类型为long。
-
Data Length (32 bits)
序列化后的内容长度(可变部分),按字节计数。int类型。
-
Variable Part
被特定的序列化类型(由序列化 ID 标识)序列化后,每个部分都是一个 byte [] 或者 byte
-
如果是请求包 ( Req/Res = 1),则每个部分依次为:
-
Dubbo version
-
Service name
-
Service version
-
Method name
-
Method parameter types
-
Method arguments
-
Attachments
-
-
如果是响应包(Req/Res = 0),则每个部分依次为:
-
返回值类型(byte),标识从服务器端返回的值类型:
-
返回空值:RESPONSE_NULL_VALUE 2
-
正常响应值: RESPONSE_VALUE 1
-
异常:RESPONSE_WITH_EXCEPTION 0
-
返回值:从服务端返回的响应bytes
-
注意: 对于(Variable Part)变长部分,当前版本的Dubbo 框架使用json序列化时,在每部分内容间额外增加了换行符作为分隔,请在Variable Part的每个part后额外增加换行符, 如:
Dubbo version bytes (换行符)
Service name bytes (换行符)
Dubbo 协议的优缺点
-
优点
协议设计上很紧凑,能用 1 个 bit 表示的,不会用一个 byte 来表示,比如 boolean 类型的标识。 请求、响应的 header 一致,通过序列化器对 content 组装特定的内容,代码实现起来简单。 - 可以改进的点
类似于 http 请求,通过 header 就可以确定要访问的资源,而 Dubbo 需要涉及到用特定序列化协议才可以将服务名、方法、方法签名解析出来,并且这些资源定位符是 string 类型或者 string 数组,很容易转成 bytes,因此可以组装到 header 中。类似于 http2 的 header 压缩,对于 rpc 调用的资源也可以协商出来一个int来标识,从而提升性能,如果在header上组装资源定位符的话,该功能则更易实现。
通过 req/res 是否是请求后,可以精细定制协议,去掉一些不需要的标识和添加一些特定的标识。比如status,twoWay标识可以严格定制,去掉冗余标识。还有超时时间是作为 Dubbo 的 attachment 进行传输的,理论上应该放到请求协议的header中,因为超时是网络请求中必不可少的。提到 attachment ,通过实现可以看到 attachment 中有一些是跟协议 content中已有的字段是重复的,比如 path和version等字段,这些会增大协议尺寸。
-
Dubbo 会将服务名com.alibaba.middleware.hsf.guide.api.param.ModifyOrderPriceParam,转换为Lcom/alibaba/middleware/hsf/guide/api/param/ModifyOrderPriceParam;,理论上是不必要的,最后追加一个;即可。
-
Dubbo 协议没有预留扩展字段,没法新增标识,扩展性不太好,比如新增响应上下文的功能,只有改协议版本号的方式,但是这样要求客户端和服务端的版本都进行升级,对于分布式场景很不友好。